01. Why do you implement column tables instead of row tables?
There are 2 correct answers to this question.
a) Data volumes are large
b) Data is suitable for partitioning
c) High performance for transaction processing is required
d) Records will be updated frequently
02. What does SQLScript provide to extend standard SQL?
There are 2 correct answers to this question.
a) Integrated source code version management
b) Support for ABAP syntax
c) Additional data types for the definition of text and spatial data
d) Features to push processing to the database
03. In SAP HANA Series Data processing, what is the definition of a profile?
Please choose the correct answer.
a) A variant of data set, such as actual, forecast, or long-term plan
b) The granularity of time intervals, such as day, hour, or minute
c) The values that you are storing, such as temperature, energy consumption, or speed
d) The object you collect data against, such as house, building, or town
04. Which of the following tasks are required to get the database objects created in the HDI container?
There are 2 correct answers to this question.
a) Build the MTA project.
b) Explicitly build the HDB module instead of the MTA project.
c) Create at least one namespace in the HDB module.
d) Assign the project to a space to which you have developer authorizations.
05. What can you discover using Data Lineage?
Please choose the correct answer.
a) Access statistics
b) Underlying calculation views and tables
c) Frequency of load
d) Data changes since last refresh
06. In a calculation view, you use a rank node to identify the purchase orders with the highest total amount. The expected output includes the top orders that represent 15% of the total numbers of orders placed by each customer.
How do you set the Aggregation Function and Result Set Type properties of the rank node to get the expected result?
Please choose the correct answer.
a) Aggregation Function: Sum
Result Set Type: Absolute
b) Aggregation Function: Rank
Result Set Type: Absolute
c) Aggregation Function: Row
Result Set Type: Percentage
d) Aggregation Function: Sum
Result Set Type: Percentage
07. Which of the following are types of calculation view?
There are 2 correct answers to this question.
a) Cube
b) Virtual
c) Dimension
d) Composite
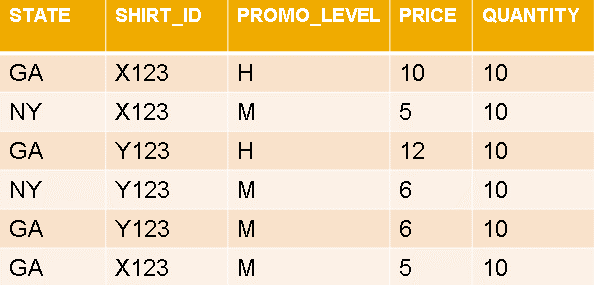
08. You are building a cube calculation view with an aggregation node that calculates total sales, based on the data shown in the graphic.
The price may vary based on SHIRT_ID and PROMO_LEVEL only. The calculation is Total Sales = PRICE * QUANTITY.
How do you ensure accurate results, regardless of the columns in the query output?
Please choose the correct answer.
a) Set the Keep Flag property for SHIRT_ID
b) Set the Dynamic Partition property for SHIRT_ID and PROMO_LEVEL.
c) Set the Calculate before Aggregation property.
d) Set the Keep Flag property for SHIRT_ID and PROMO_LEVEL.
09. Which of the following approaches can be used to implement union pruning?
There are 2 correct answers to this question.
a) Define a constant value for each data source in the Union node.
b) Define a restricted column and include it in both data sources of a union.
c) Define the cardinality between the data sources.
d) Define union pruning conditions in a pruning configuration table.
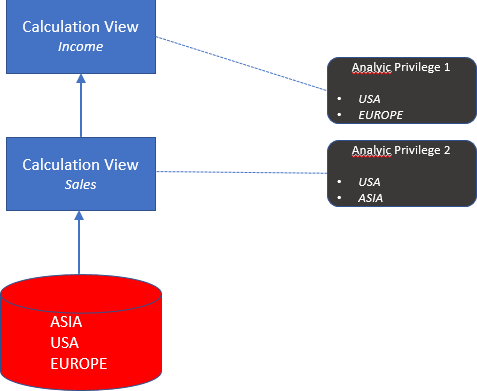
10. One SQL analytic privilege authorizes you to view data for Europe and the USA in the sales calculation view, and another one authorizes you to view data for Asia and the USA in the income calculation view. The income view uses the sales view as a data source.
Both calculation views check SQL analytic privileges.
What data can you visualize when consuming the income calculation view?
Please choose the correct answer.
a) Data from the USA
b) Data from Europe and the USA
c) Data from Europe, Asia, and the USA
d) Data from Asia and the USA
 The SAP HANAIMP 18 Certification Sample Question Set is prepared to make you familiar with actual SAP C_HANAIMP_18 exam question format and exam pattern. To get familiar with more exam properties, we suggest you to try our Sample SAP HANAIMP 18 Certification Practice Exam.
The SAP HANAIMP 18 Certification Sample Question Set is prepared to make you familiar with actual SAP C_HANAIMP_18 exam question format and exam pattern. To get familiar with more exam properties, we suggest you to try our Sample SAP HANAIMP 18 Certification Practice Exam.